Сегодня на мероприятии Vision 2024 компания Intel представила множество новых продуктов, среди которых ИИ-ускорители Gaudi 3. По заявлениям создателей, они позволяют обучать нейросети в 1,7 раза быстрее, на 50 % увеличить производительность инференса и работают на 40 % эффективнее конкурирующих H100 от NVIDIA, которые являются самыми популярными на рынке.
Источник изображений: Intel
Gaudi 3 — третье поколение ускорителей ИИ, появившихся благодаря приобретению Intel в 2019 году компании Habana Labs за $2 млрд. Массовое производство Gaudi 3 для OEM-производителей серверов начнётся в третьем квартале 2024 года. Помимо этого, Gaudi 3 будет доступен в облачном сервисе Intel Developer Cloud для разработчиков, что позволит потенциальным клиентам испытать возможности нового чипа.

Gaudi 3 использует ту же архитектуру и основополагающие принципы, что и его предшественник, но при этом он выполнен по более современному 5-нм техпроцессу TSMC, тогда как в Gaudi 2 использованы 7-нм чипы. Ускоритель состоит из двух кристаллов, на которые приходится 64 ядра Tensor Processing Cores (TPC) пятого поколения и восемь матричных математических движков (MME), а также 96 Мбайт памяти SRAM с пропускной способностью 12,8 Тбайт/с. Вокруг установлено 128 Гбайт HBM2e с пропускной способностью 3,7 Тбайт/с. Также Gaudi 3 укомплектован 24 контроллерами Ethernet RDMA с пропускной способностью по 200 Гбит/с, которые обеспечивают связь как между ускорителями в одном сервере, так и между разными серверами в одной системе.

Gaudi 3 будет выпускаться в двух формфакторах. Первый — OAM (модуль ускорителя OCP) HL-325L, использующийся в высокопроизводительных системах на основе ускорителей вычислений. Этот ускоритель получит TDP 900 Вт и производительность 1835 терафлопс в FP8. Модули OAM устанавливаются по 8 штук на UBB-узел HLB-325, которые можно объединять в системы до 1024 узлов. По сравнению с прошлым поколением, Gaudi 3 обеспечивает вдвое большую производительность в FP8 и вчетверо — в BF16, вдвое большую пропускную способность сети и 1,5 раза — памяти.
OAM устанавливаются в универсальную плату, поддерживающую до восьми модулей. Модули и платы уже отгружены партнёрам, но массовые поставки начнутся лишь к концу года. Восемь OAM на плате HLB-325 дают производительность 14,6 петафлопс в FP8, остальные характеристики масштабируются линейно.
Второй формфактор — двухслотовая карта расширения PCIe с TDP 600 Вт. По заявлениям Intel, несмотря на заметно меньший TDP этой версии, производительность в FP8 осталась той же — 1835 терафлопс. А вот масштабируемость хуже — модули рассчитаны на работу группами по четыре. Gaudi 3 в данном формфакторе появятся в 4 квартале 2024 года.
Dell, HPE, Lenovo и Supermicro уже поставили клиентам образцы систем с Gaudi 3 с воздушным охлаждением, а в ближайшее время должны появится модели с жидкостным охлаждением. Массовое производство начнётся лишь в 3 и 4 кварталах 2024 года соответственно.
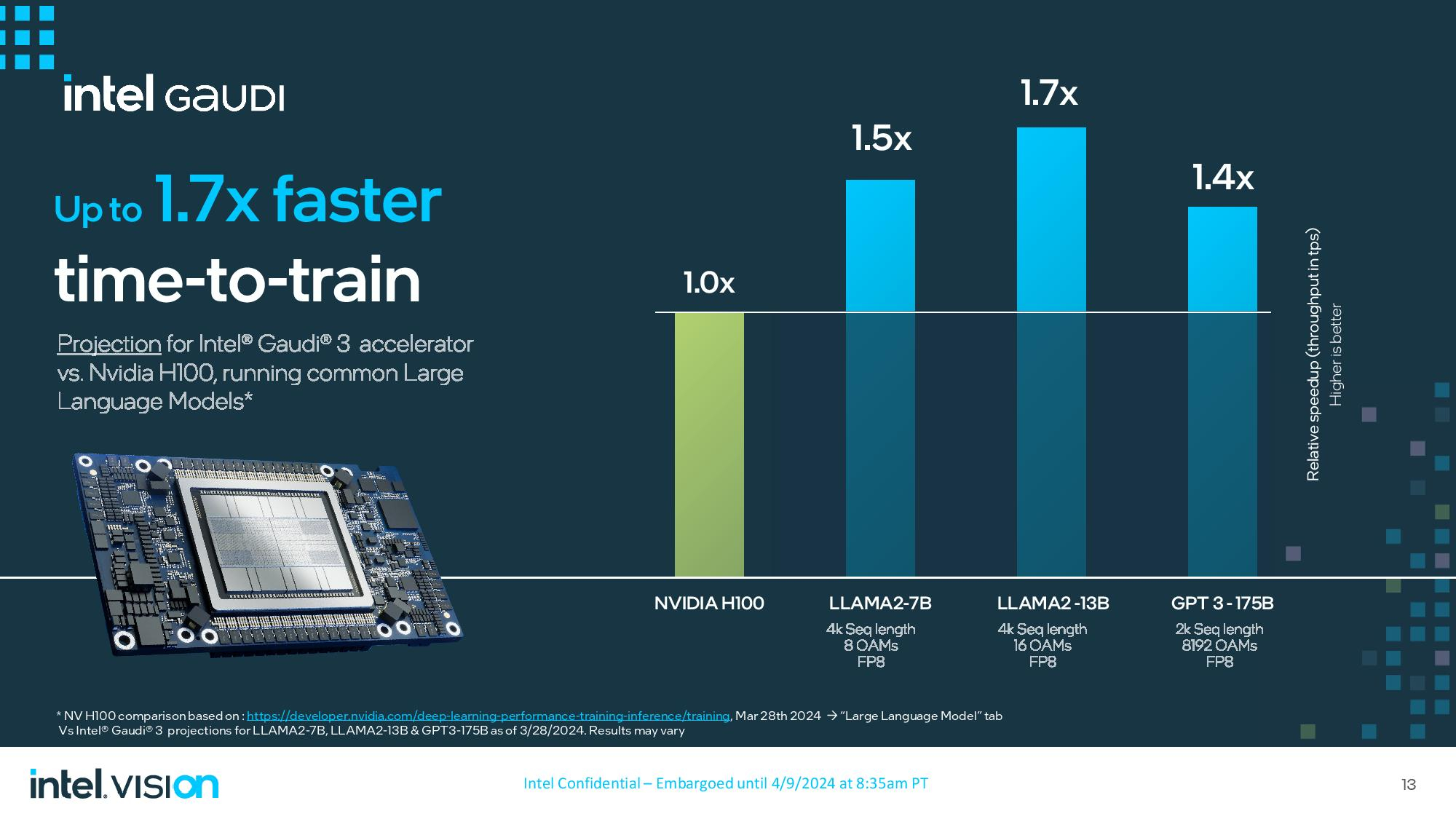
Intel также поделилась собственными тестами производительности, сравнив Gaudi 3 с системами на основе H100. По словам Intel, Gaudi 3 справляется с обучением нейросетей в 1,5–1,7 раза быстрее. Сравнение велось на моделях LLAMA2-7B и LLAMA2-13B на системах с 8 и 16 ускорителями, а также на модели GPT 3-175B на системе с 8192 ускорителями. Intel не стала сравнивать системы на Gaudi 3 с системами на H200 от NVIDIA, у которого на 76 % больше памяти, а её пропускная способность выше на 43 %.
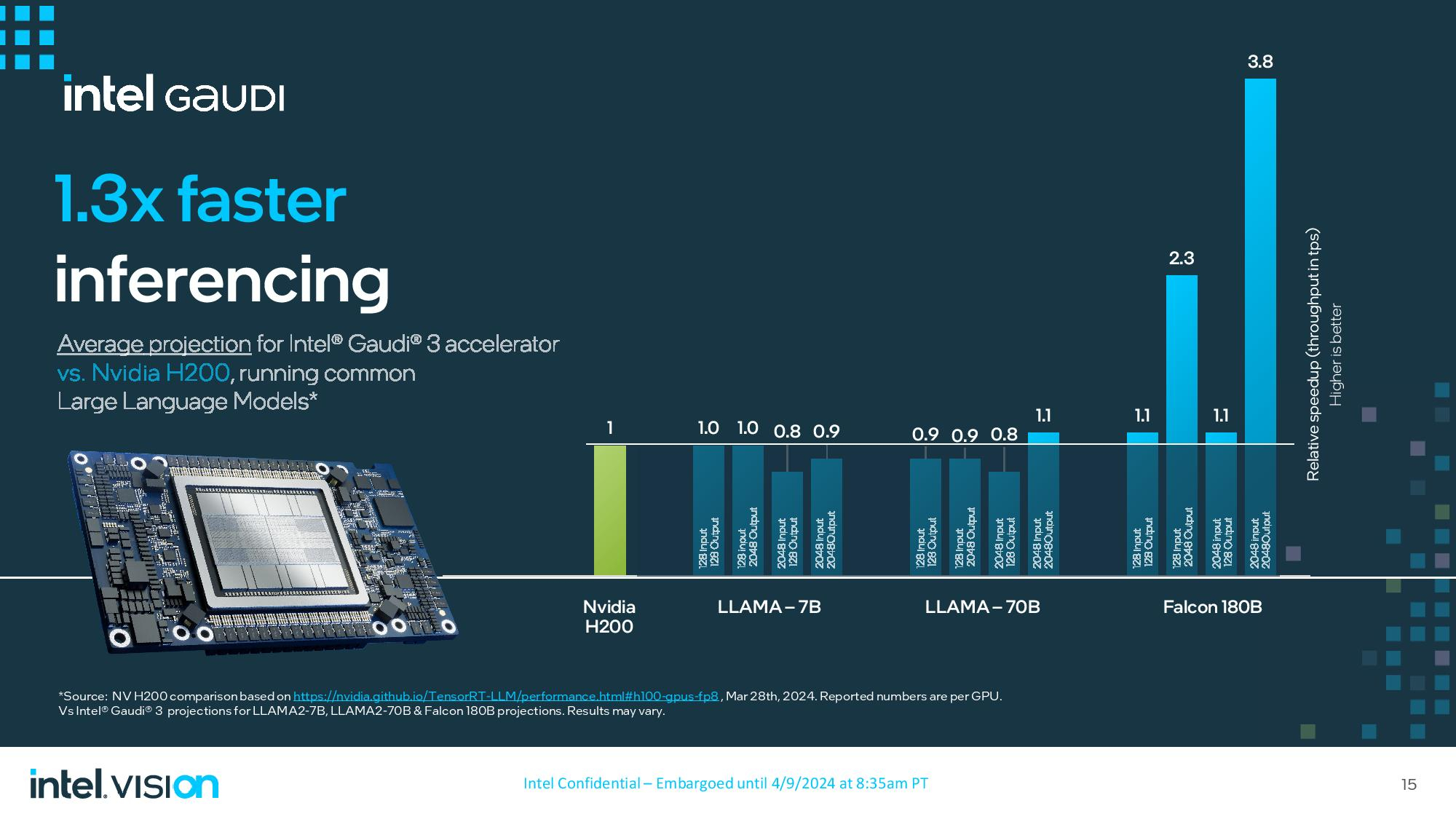
Intel сравнила Gaudi 3 с H200 в инференсе, но уже не кластерами, а отдельным модулем. В пяти тестах с LLAMA2-7B/70B производительность Gaudi 3 оказалась на 10–20 % ниже, в двух равна и в одном чуть выше H200. При этом Intel заявляет о 2,6-кратном преимуществе в энергопотреблении по сравнению с H100.
Источник: 3DNews