Сегодня Google объявила о запуске новой большой языковой модели Gemini. Вместе с ней компания представила свой новый ИИ-ускоритель Cloud TPU v5e (Tensor processing unit — тензорный процессор). Кластер на базе новых TPU состоит из 8960 чипов v5p и оснащён самым быстрым интерконнектом Google — скорость передачи данных может достигать 4800 Гбит/с на чип.
Источник изображений: Google
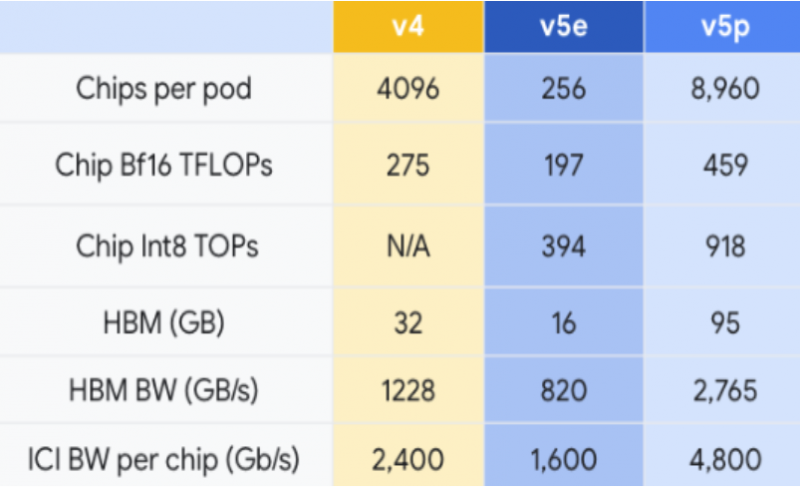
Cloud TPU v5e оснащён 95 Гбайт памяти HBM3 с пропускной способностью 2765 Гбайт/с. Производительность в целочисленных операциях INT8 составляет 918 TOPS (триллионов операций в секунду), тогда как производительность в вычислениях на числах с плавающей запятой BF16 составляет 459 Тфлопс.
Google утверждает, что новые чипы значительно быстрее, чем образец предыдущего поколения TPU v4. Новый Cloud TPU v5p предложит двукратное увеличение производительности в операциях с плавающей запятой (FLOPS) и трёхкратное увеличение объёма памяти с высокой пропускной способностью.
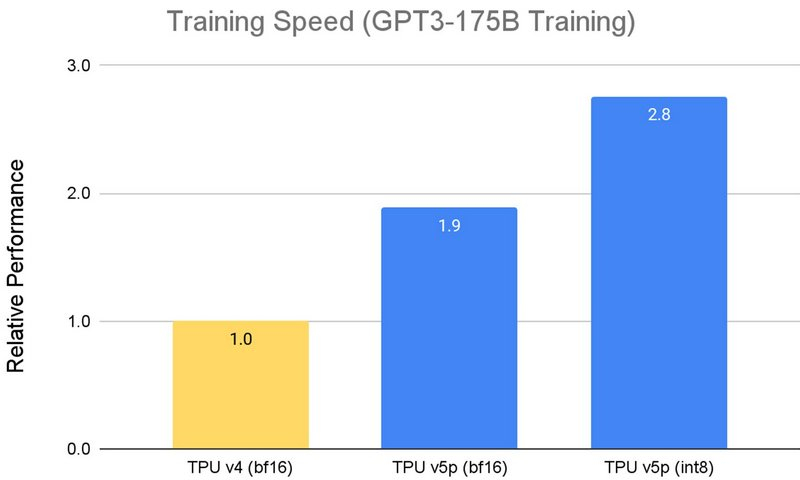
По словам Google, новые ускорители TPU v5p способны обучать большие языковые модели, например GPT-3 со 175 млрд параметров, в 2,8 раза быстрее, чем TPU v4, и при этом с меньшими затратами энергии. Более того, благодаря второму поколению SparseCore, TPU v5p может обучать embedding-dense модели в 1,9 раза быстрее, чем TPU v4. Помимо повышения производительности, TPU v5p обеспечивает вдвое более высокий уровень масштабируемости, чем TPU v4, что в сочетании с удвоением производительности обеспечивает в четыре раза больше Флопс на кластер.
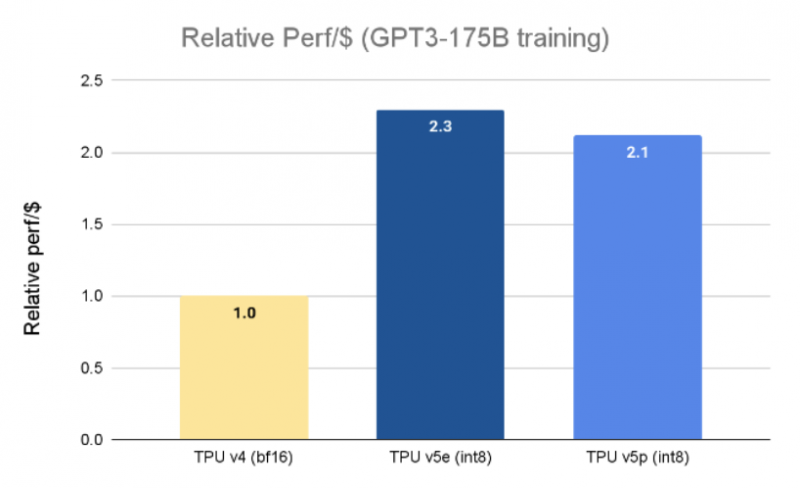
Что интересно, по производительности на доллар v5p слегка проигрывает представленным недавно ускорителям TPU v5e. Однако последние можно собирать в кластеры лишь до 256 чипов, а один чип обеспечит лишь 197 Тфлопс в BF16 против 275 Тфлопс у TPU v4 и 459 Тфлопс у TPU v5p.
«На ранней стадии использования Google DeepMind и Google Research демонстрировали двукратное ускорение рабочих нагрузок по обучению LLM на основе чипов TPU v5p по сравнению с производительностью, снятой с чипов текущего поколения TPU v4, – пишет Джефф Дин (Jeff Dean), главный научный сотрудник Google DeepMind и Google Research. – Широкая поддержка ML-фреймворков, таких как JAX, PyTorch, TensorFlow, и инструментов оркестровки позволят нам ещё эффективнее масштабироваться, используя чипы v5p. Благодаря второму поколению SparseCore мы также видим значительное улучшение производительности рабочих нагрузок при выполнении встраиваний. TPU жизненно важны для обеспечения наших самых масштабных исследований и инженерных работ на передовых моделях, таких как Gemini».
Источник: 3DNews