Компания Adobe официально представила новую генеративную нейросеть Firefly Video Model, которая предназначена для работы с видео и стала частью приложения Premiere Pro. С помощью этого инструмента пользователи смогут дополнять отснятый материал, а также создавать ролики на основе статичных изображений и текстовых подсказок.
Источник изображений: Adobe
Функция Generative Extend на базе упомянутой нейросети в рамках бета-тестирования становится доступной пользователям Premiere Pro. Она позволит продлить видео на несколько секунд в начале, конце или каком-то другом отрезке ролика. Это может оказаться полезным, если в процессе монтажа нужно скорректировать мелкие недочёты, такие как смещение взгляда человека в кадре или лишние движения.
С помощью Generative Extend можно продлить ролик лишь на две секунды, поэтому он подходит только для внесения небольших изменений. Данный инструмент работает с разрешением 720p или 1080p с частотой 24 кадра в секунду. Функция также подходит для увеличения продолжительности аудио, но есть ограничения. Например, пользователь может продлить какой-либо звуковой эффект или окружающий шум до 10 секунд, но сделать это же с записями разговором или музыкальными композициями не удастся.
В веб-версии Firefly появились два новых инструмента генерации видео. Речь идёт о функциях Text-to-Video и Image-to-Video, которые, как можно понять из названия, позволяют создавать видео на основе текстовых подсказок и статических изображений. На данном этапе обе функции находятся на этапе ограниченного бета-тестирования, поэтому могут быть доступны не всем пользователям веб-версии Firefly.
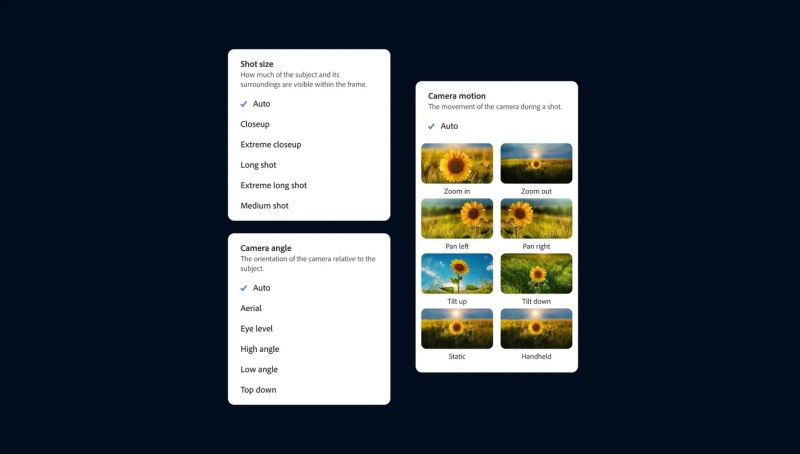
Text-to-Video работает аналогично другим ИИ-генераторам видео, таким как Sora от OpenAI. Пользователю нужно ввести текстовое описание желаемого результата и запустить процесс генерации ролика. Поддерживается имитация разных стилей, а сгенерированные ролики можно доработать с помощью набора «элементов управления камерой», которые позволяют имитировать такие вещи, как угол наклона камеры, движение и менять расстояние съёмки.
Image-to-Video позволяет добавить к текстовому описанию статическое изображение, чтобы генерируемые ролики более точно соответствовали требованиям пользователя. Adobe предлагает использовать этот инструмент, в том числе, для пересъёмки отдельных фрагментов, генерируя новые видео на основе отдельных кадров из существующих роликов. Однако опубликованные примеры дают понять, что этот инструмент, по крайней мере на данном этапе, не позволит отказаться от пересъёмки, поскольку он не совсем точно воспроизводит все имеющиеся на изображении объекты. Ниже пример оригинального видео и ролика, сгенерированного на основе кадра из оригинала.
Снимать длинные ролики с помощью этих инструментов не получится, по крайней мере на данном этапе. Функции Text-to-Video и Image-to-Video позволяют создавать видео продолжительностью 5 секунд в качестве 720p с частотой 24 кадра в секунду. Для сравнения, OpenAI утверждает, что её ИИ-генератор Sora может создавать видео длиной до минуты «при сохранении визуального качества и соблюдении подсказок пользователя». Однако этот алгоритм всё ещё недоступен широкому кругу пользователей, несмотря на то, что с момента его анонса прошло несколько месяцев.
Для создания видео с помощью Text-to-Video, Image-to-Video и Generative Extend требуется около 90 секунд, но в Adobe сообщили о работе над «турборежимом» для сокращения времени генерации. В компании отметили, что созданные на основе Firefly Video Model инструменты «коммерчески безопасны», поскольку нейросеть обучается на контенте, который Adobe разрешено использовать.
Источник: 3DNews