Источник изображений: Ericsson
Фактически Ericsson подтвердила «коммерческую поддержку» исключительно решений Intel, в то время как в случае AMD, Arm и NVIDIA всё по-прежнему ограничивается «поддержкой прототипов». Несмотря на многолетние заявления отрасли о необходимости разнообразия микросхем в экосистеме vRAN, прогресс, похоже, застопорился. Кроме того, интеграция ИИ в ПО RAN добавляет новые уровни сложности, которые могут ещё больше укрепить зависимость компании от «железа» одного вендора.
Отраслевые наблюдатели по-прежнему скептически относятся к стремлению Ericsson к «единому программному стеку» для гетерогенных аппаратных платформ. Хотя аппаратная и программная дезагрегация достижима на более высоких уровнях (L2/L3), PHY-уровень L1 — наиболее ресурсоёмкая часть стека — остаётся сильно оптимизированным для конкретного «кремния». Первоначально Ericsson рассчитывала на переносимость L1-кода между x86 (в т.ч. AMD) и Arm SVE2 (NVIDIA Grace) для соответствия возможностям Intel AVX-512. Однако достижение высокой производительности на этих платформах без существенного рефакторинга остается серьёзной инженерной проблемой.
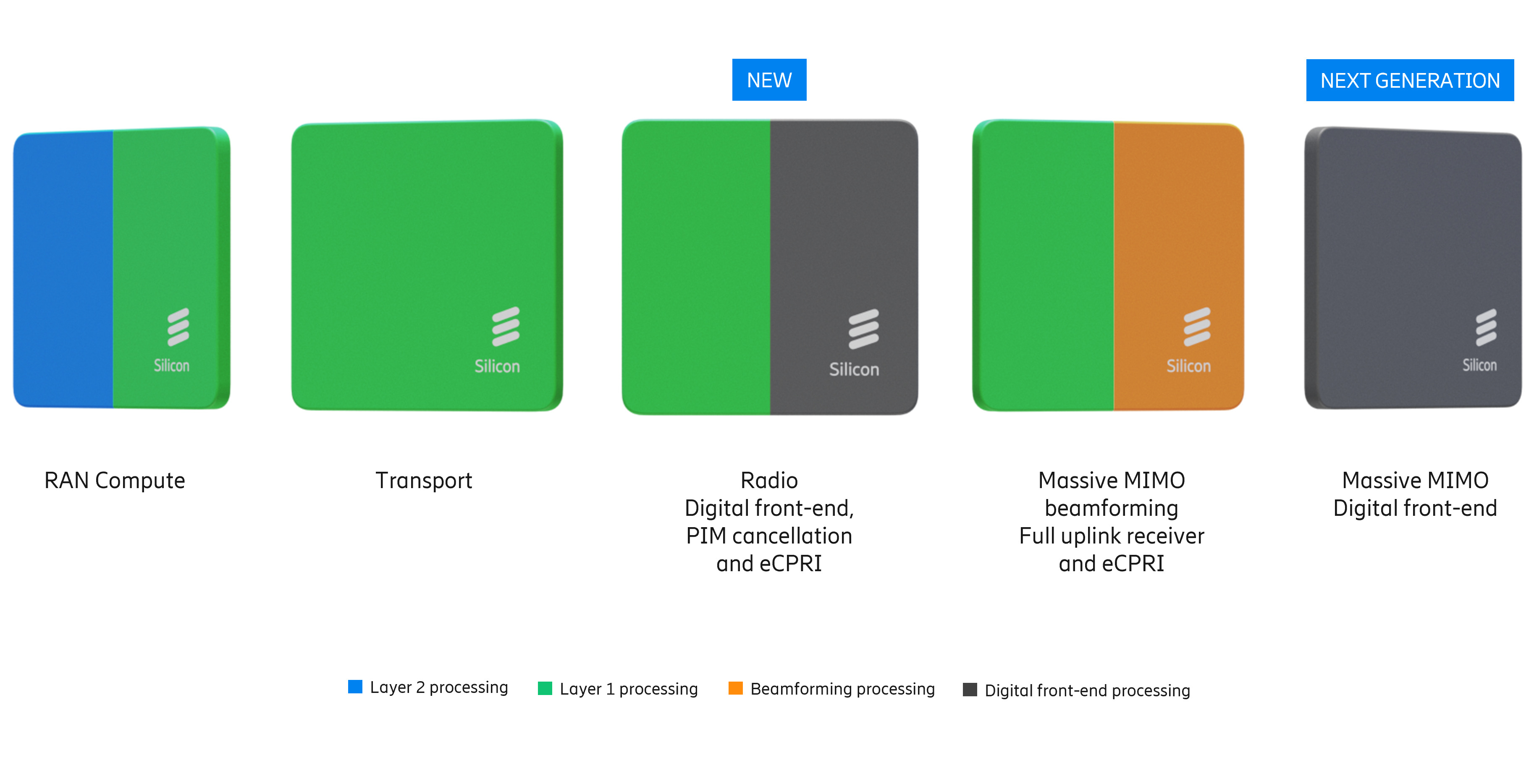
Критическим узким местом в обработке L1-трафика является коррекция ошибок (Forward Error Correction), которая традиционно требует выделенного аппаратного ускорения. Ericsson первоначально полагалась на разгрузку с переносом задач FEC на дискретные PCIe-ускорители Intel. Затем Intel внедрила ускорение FEC в Xeon EE в рамках vRAN Boost. Попытки использовать FPGA AMD показали их невысокую энергоэффективность, а GPU NVIDIA оказались слишком дороги для такой задачи.
Однако развитие AI-RAN изменило экономику, поскольку теперь ускорители можно использовать как для RAN, так и для ИИ-задач. Так, Ericsson заинтересовали тензорные процессоры Google (TPU). Тем не менее, несмотря на стремление к созданию «единого ПО», планы Ericsson подтверждают существование проблем в реализации этой идеи. В то время как уровни L2 и выше используют универсальную кодовую базу для всех аппаратных платформ, уровень L1 требует адаптации под конкретные чипы.
Чтобы избежать зависимости от одного поставщика чипов, компания уделяет приоритетное внимание развитию HAL (Hardware Abstraction Layers), что позволит портировать ПО на разные аппаратные платформы с минимальными изменениями. Основные инициативы включают внедрение интерфейса BBDev (Baseband Device) для отделения ПО RAN от базового аппаратного обеспечения. Рассматривается даже возможность интеграции с NVIDIA CUDA, но здесь многое зависит от более широкой отраслевой стандартизации.
Что касается радиосвязи, менее подверженной полной виртуализации, Ericsson встраивает процессоры Neural Network Accelerators (NNA) непосредственно в радиомодули. Эти программируемые матричные ядра оптимизированы для обработки данных в системах Massive MIMO, обеспечивая формирование луча и оценку канала за доли миллисекунды при соблюдении строгих ограничений по мощности. Новые AI-радиомодули оснащены ASIC Ericsson с NNA. Утверждается, что они расширяют возможности локального инференса в радиосистемах Massive MIMO, обеспечивая оптимизацию в реальном времени.
Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER. | Можете написать лучше? Мы всегда рады новым авторам.
Материалы по теме:
3DNews